 Java8--Lambda 表达式、Stream 和时间 API
Java8--Lambda 表达式、Stream 和时间 API
自Java 9开始,Java采用了每半年发布一个版本的快速迭代模式。尽管新版本不断推出,但由于Java 9引入的模块化系统变动较大,许多企业项目仍在使用Java 8。
Java 8作为一个长期支持版本(LTS),引入了函数式编程的核心特性——Lambda表达式和Stream API,这些特性从根本上改变了Java的编程范式。
本文将深入探讨Java 8的三大核心特性:Lambda表达式、Stream API和新的时间API,并通过实际案例帮助读者掌握这些强大的工具。
# 一、Lambda表达式
Lambda表达式是Java 8引入的最重要特性之一,它让Java正式支持了函数式编程。在此之前,Java程序员只能通过匿名内部类来实现类似功能,代码冗长且不够直观。
Lambda表达式本质上是一个匿名函数,主要用于实现函数式接口(Functional Interface)。
所谓函数式接口,就是只定义了一个抽象方法的接口,在Java 8中用@FunctionalInterface注解来标识。
看一下我们熟悉的Runnable,Java 8的源码如下:
@FunctionalInterface
public interface Runnable {
public abstract void run();
}
平常我们把一个匿名的Runnable对象传给Thread,如:
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("hello");
}
}).run();
用Lambda的话:
new Thread(() -> {
System.out.println("hello");
}).run();
因为这里方法体只有一句代码,那么可以更简洁一些:
new Thread(() -> System.out.println("hello")).run();
# 1、Lambda基本结构
一个参数:
Consumer<String> consumer = event -> System.out.println("hello " + event);
两个参数:
Comparator<String> comp = (first, second) -> Integer.compare(first.length(), second.length());
无参数:
Runnable runnable = () -> System.out.println("hello");
Lambda表达式体只有一条语句时,可以省略大括号和return关键字:
Comparator<String> comp = (first, second) -> first.length() - second.length();
# 2、通用的函数式接口
为了方便,Java 8中定义了许多通用的函数式接口,在java.util.function包中,其实以前我们在Guava中见到过这些类:
Predicate<T>- 传入一个参数,返回一个boolean结果,方法为boolean test(T t)BiPredicate<T, U>- 传入两个参数,返回一个boolean结果,方法为boolean test(T t, U u)Consumer<T>- 传入一个参数,无返回值,纯消费,方法为void accept(T t)BiConsumer<T, U>- 传入两个参数,无返回值,纯消费,方法为void accept(T t, U u)Function<T, R>- 传入一个参数,返回一个结果,方法为R apply(T t)BiFunction<T, U, R>- 传入两个参数,返回一个值,方法为R apply(T t, U u)Supplier<T>- 无参数传入,返回一个结果,方法为T get()UnaryOperator<T>- 一元操作符,继承Function,传入参数的类型和返回类型相同BinaryOperator<T>- 二元操作符,传入的两个参数的类型和返回类型相同,继承BiFunction
# 3、方法引用操作符
先看一个例子:
button.setOnAction(event -> System.out.println(event))
//等价于:
button.setOnAction(System.out::println)
可以看到一个新的操作符::,在Java 8中它是方法引用操作符。
先定义一个类,便于下面举例使用:
private static class TUser {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
方法引用操作符主要是四种用法:
- 对象
::实例方法,如
TUser tUser = new TUser();
Supplier<String> supplier = tUser::getName;
//tUser::getName 等价于 tUser -> tUser.getName()
- 类
::静态方法,如
button.setOnAction(System.out::println);
//或
// Math::pow 等价于 (x, y) -> Math.pow(x, y)
- 类
::实例方法,如
this::equals
//或
Function<TUser, String> function = TUser::getName;
//TUser::getName 等价于 tUser -> tUser.getName()
需要注意对象::实例方法和类::实例方法的不同
- 构造器引用
// int[]::new 等价于 x -> new int[x]
List<Object> list = new ArrayList<Object>();
list.stream().toArray(String[]::new);
# 4、接口中的默认方法
Java 8允许在接口中定义默认方法(default method),这是一个重大的语言特性改进。默认方法使得接口可以包含方法实现,从而实现了接口的演进而不破坏现有实现类。这个特性类似于其他语言中的Mixin机制。
需要用default关键字,直接用JDK中的例子来看吧,拿我们熟悉的java.util.List接口来说,就有了新的接口默认方法:
default void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
ListIterator<E> i = this.listIterator();
for (Object e : a) {
i.next();
i.set((E) e);
}
}
# 5、LambdaMetafactory
LambdaMetafactory是Java 8提供的一个强大工具,它可以在运行时动态生成Lambda表达式,从而实现比反射更高效的动态方法调用。这个特性在需要高性能动态调用的场景中非常有用。
在fastjson2中,LambdaMetafactory得到了大量使用,可以参考:fastjson2为什么这么快? (opens new window)
我们来看一下函数映射怎么替代反射:
@Test
void direct() {
String toBeTrimmed = " text with spaces ";
System.out.println(toBeTrimmed.trim());
Supplier<String> trimSupplier = toBeTrimmed::trim;
System.out.println(trimSupplier.get());
Function<String, String> trimFunc = String::trim;
System.out.println(trimFunc.apply(toBeTrimmed));
}
@Test
void reflection() throws NoSuchMethodException, InvocationTargetException, IllegalAccessException {
String toBeTrimmed = " text with spaces ";
Method reflectionMethod = String.class.getMethod("trim");
Object invoke = reflectionMethod.invoke(toBeTrimmed);
System.out.println(invoke);
}
@Test
void methodHandle() throws Throwable {
String toBeTrimmed = " text with spaces ";
Lookup lookup = MethodHandles.lookup();
MethodType mt = MethodType.methodType(String.class);
MethodHandle mh = lookup.findVirtual(String.class, "trim", mt);
Object invoke = mh.invoke(toBeTrimmed);
System.out.println(invoke);
}
@Test
void lambdametaFactory1() throws Throwable {
String toBeTrimmed = " text with spaces ";
Lookup lookup = MethodHandles.lookup();
MethodType mt = MethodType.methodType(String.class);
MethodHandle mh = lookup.findVirtual(String.class, "trim", mt);
CallSite callSite = LambdaMetafactory.metafactory(lookup, "get", MethodType.methodType(Supplier.class, String.class),
MethodType.methodType(Object.class), mh, MethodType.methodType(String.class));
Supplier<String> lambda = (Supplier<String>) callSite.getTarget().bindTo(toBeTrimmed).invoke();
System.out.println(lambda.get());
}
@Test
void lambdametaFactory2() throws Throwable {
String toBeTrimmed = " text with spaces ";
Lookup lookup = MethodHandles.lookup();
MethodType mt = MethodType.methodType(String.class);
MethodHandle mh = lookup.findVirtual(String.class, "trim", mt);
CallSite callSite = LambdaMetafactory.metafactory(lookup, "apply", MethodType.methodType(Function.class),
MethodType.methodType(Object.class, Object.class), mh, MethodType.methodType(String.class, String.class));
Function<String, String> trimFunc = (Function<String, String>) callSite.getTarget().invokeExact();
System.out.println(trimFunc.apply(toBeTrimmed));
}
上述代码展示了四种不同的方法调用方式:
- 直接调用:性能最优,编译时确定
- 反射调用:灵活但性能较差,有额外的安全检查开销
- 方法句柄:比反射略快,但仍有性能损耗
- LambdaMetafactory:接近直接调用的性能,同时保持动态性
在高性能场景下,LambdaMetafactory是替代反射的最佳选择。
# 二、Stream API
Stream API是Java 8引入的另一个革命性特性,它提供了一种声明式的数据处理方式。相比传统的命令式编程,Stream API让代码更加简洁、易读,同时还能轻松实现并行处理。
让我们先看一个简单的例子:
List<String> words = Arrays.asList("Hello", "Stream", "API", "Performance", "Optimization");
// 传统方式:使用for循环
int count = 0;
for (String word : words) {
if (word.length() > 5) {
count++;
}
}
// Stream方式:声明式编程
long streamCount = words.stream()
.filter(w -> w.length() > 5)
.count();
Java 8之后所有的集合对象都有stream()方法,它会返回一个Stream对象,Stream对象和集合的主要区别是:
- Stream自己不存储元素
- Stream操作不会改变源对象,它会返回一个持有结果的新Stream
- Stream可能是延迟执行的,等到需要结果的时候才执行
如果要获得一个并行的Stream,可以使用words.parallelStream()。需要注意的是,并行流并不总是更快,对于小数据量或简单操作,并行化的开销可能超过其带来的性能提升。
# 1、创建Stream
创建主要有这么几种方式:
Stream.of(arr)- of函数接受一个值或一个数组Stream.empty()- 一个空的流Stream.generate(() -> "Echo")- 按照函数逻辑生成一个值Stream.generate(Math::random)- 同上Stream.iterate(BigInteger.ZERO, n -> n.add(BigInteger.ONE))- 无限序列。第一个参数是初始值,第二个参数是对前一个值进行的操作Stream<String> lines = Files.lines(path)- 有的函数直接返回一个Stream
# 2、filter、map和flatMap方法
说一下Stream的几个主要方法。
filter在前面已经体验过了,来看看map方法,它将流中的每个元素转换为另一种形式:
Stream<String> lowercaseWords = words.stream().map(String::toLowerCase);
Stream<Character> firstChars = words.stream().map(s -> s.charAt(0));
flatMap用于将多个Stream合并为一个Stream。它常用于处理嵌套结构:
// 将每个单词拆分为字符流并合并
Stream<Character> letters = words.stream()
.flatMap(word -> word.chars().mapToObj(c -> (char) c));
// 处理嵌套集合
List<List<String>> nestedList = Arrays.asList(
Arrays.asList("a", "b"),
Arrays.asList("c", "d")
);
List<String> flatList = nestedList.stream()
.flatMap(Collection::stream)
.collect(Collectors.toList()); // [a, b, c, d]
# 3、提取子流和组合流
直接看例子:
words.stream().limit(100); // limit()返回一个包含n个元素的新流
words.stream().skip(5); // 会丢弃掉前面的n个元素
Stream.concat(words1, words2); // 把两个流连接起来
Stream.iterate(1, n -> n + 1).peek(e -> System.out.println(e)).limit(20).toArray(); // peek函数是一个中间操作,一般用于调试比较多
# 4、有状态的转换
之前介绍的流转换都是无状态的,结果不依赖之前的元素。
看一下有状态的转换,也就是元素之间有依赖关系的转换:
Stream.of(arr).distinct();
words.sorted(Comparator.comparing(String::length).reversed());
# 5、简单的聚合方法
聚合方法一般都是终止操作,看代码:
words.max(String::compareToIgnoreCase);
words.filter(...).findFirst();
words.filter(...).findAny();
list.stream().anyMatch(s -> s.startsWith(""));
list.stream().noneMatch(s -> s.startsWith(""));
# 6、Optional类型
Optional主要用来解决空值的问题,直接看例子:
Optional<Integer> num = Optional.of(100);
num.ifPresent(v -> System.out.println(v)); // 不为null,才调用里面的方法
num = num.map(v -> v = 19);
System.out.println(num.get());
Optional<String> str = Optional.empty();
System.out.println(str.orElse("123")); // 默认值
str.orElseGet(() -> "");
Optional.ofNullable(""); // 如果入参是null,返回empty()
Optional<Double> num1 = Optional.of(12.3);
Optional<String> str1 = num1.flatMap((x) -> Optional.ofNullable(x + "")); // 转换类型
感觉Optional中最常用的就是orElse()方法了。
# 7、reduce聚合函数
在大数据处理中,MapReduce是比较经典的思想了,来自于Lisp语言的map和reduce函数。
前面讲过map函数,主要是用来分发并获得副本,下面来看看reduce聚合函数:
Stream<Integer> values = Stream.of(1, 2, 3, 4);
Optional<Integer> sum = values.reduce((x, y) -> x + y);
values.reduce(Integer::sum);
reduce的参数是BinaryOperator接口,接口中的方法要有两个入参,这两个入参很有意思。第一个参数是累积结果值,第二个参数是当前循环值,什么意思呢?我们看到reduce入参的方法体有一个计算x+y,这是一个返回值,这个返回值在下一次循环会变成方法的第一个入参。
reduce的处理逻辑相当于下面的代码:
T result = null;
for (T element : this stream) {
result = accumulator.apply(result, element);
}
return Optional.of(result);
// accumulator = reduce入参的BinaryOperator
reduce方法还有带初始值的重载版本:
Stream<Integer> values = Stream.of(1, 2, 3, 4);
Integer sum = values.reduce(0, (x, y) -> x + y); // 有初始值,返图T而不是Optional<T>
values.reduce(Integer::sum);
reduce还有更复杂的用法:
List<String> words = new ArrayList<>();
words.add("a");
words.add("bed");
words.add("c");
int num = words.stream().reduce(0, (x, y) -> x + y.length(), Integer::sum);
System.out.println(num); // =5
可以看到这是一个统计集合中所有元素总字符数的代码。这个是reduce的重载函数,有三个入参。第一个参数是初始的result;第二个参数是一个BiFunction,用来做累计结果操作;第三个参数是一个BinaryOperator,合并两个累积结果。它的接口方法参数有两个:prevResult, nextResult,分别是前一次操作的结果和下一次操作的结果。
# 8、收集结果
Stream是一个流,如果要想把它转换为我们熟悉的集合,可以这样做:
Stream<String> stream = Stream.of("a", "b", "c");
List<String> list = stream.collect(Collectors.toList()); // 转换为List集合
stream = Stream.of("a", "b", "c", "a");
Set<String> set = stream.collect(Collectors.toSet()); // 转换为Set集合(去重)
stream = Stream.of("c", "a", "b");
TreeSet<String> treeSet = stream.collect(Collectors.toCollection(TreeSet::new)); // 转换为TreeSet(排序)
如果要收集到Map中:
// 收集到Map
List<TUser> users = Arrays.asList(
new TUser(1L, "Alice"),
new TUser(2L, "Bob")
);
Map<Long, String> idToName = users.stream()
.collect(Collectors.toMap(TUser::getId, TUser::getName));
Map<Long, TUser> idToUser = users.stream()
.collect(Collectors.toMap(TUser::getId, Function.identity())); // Function.identity()表示元素本身
// 处理键冲突的情况
List<TUser> usersWithDuplicates = Arrays.asList(
new TUser(1L, "a"),
new TUser(2L, "b"),
new TUser(1L, "c")
);
Map<Long, String> mergedMap = usersWithDuplicates.stream()
.collect(Collectors.toMap(
TUser::getId,
TUser::getName,
(existing, replacement) -> existing + "-" + replacement // 合并策略
));
mergedMap.forEach((k, v) -> System.out.println(k + ": " + v));
此外,还可以进行字符串连接操作:
List<String> list = Arrays.asList("a", "b", "c");
String result1 = list.stream().collect(Collectors.joining()); // "abc"
String result2 = list.stream().collect(Collectors.joining(", ")); // "a, b, c"
String result3 = list.stream().collect(Collectors.joining(", ", "[", "]")); // "[a, b, c]"
// 对非字符串类型进行连接
List<Integer> numbers = Arrays.asList(1, 2, 3);
String numStr = numbers.stream()
.map(Object::toString)
.collect(Collectors.joining(", ")); // "1, 2, 3"
还可以收集一些我们常用的计算方式:
List<String> words = Arrays.asList("hello", "world", "java");
// 收集统计信息
IntSummaryStatistics stats = words.stream()
.collect(Collectors.summarizingInt(String::length));
System.out.println("平均长度: " + stats.getAverage());
System.out.println("最大长度: " + stats.getMax());
System.out.println("最小长度: " + stats.getMin());
System.out.println("总长度: " + stats.getSum());
System.out.println("单词数量: " + stats.getCount());
// 只求总值
int totalLength = words.stream()
.collect(Collectors.summingInt(String::length));
// 等同于使用mapToInt
int totalLength2 = words.stream()
.mapToInt(String::length)
.sum();
求最大值、最小值:
List<TUser> users = Arrays.asList(
new TUser(1L, "Alice"),
new TUser(3L, "Bob"),
new TUser(2L, "Charlie")
);
// 使用Collectors.maxBy
Optional<TUser> maxUser = users.stream()
.collect(Collectors.maxBy(Comparator.comparing(TUser::getId)));
// 直接使用max(更简洁)
Optional<TUser> maxUser2 = users.stream()
.max(Comparator.comparing(TUser::getId));
// 找出最小值
Optional<TUser> minUser = users.stream()
.min(Comparator.comparing(TUser::getId));
maxUser.ifPresent(user -> System.out.println("最大ID用户: " + user.getName()));
minUser.ifPresent(user -> System.out.println("最小ID用户: " + user.getName()));
# 9、分组和分片
先看分组:
List<TUser> users = Arrays.asList(
new TUser(1L, "Alice"),
new TUser(2L, "Bob"),
new TUser(1L, "Charlie")
);
// 按ID分组,默认收集到List
Map<Long, List<TUser>> groupedByIdList = users.stream()
.collect(Collectors.groupingBy(TUser::getId));
// 按ID分组,收集到Set
Map<Long, Set<TUser>> groupedByIdSet = users.stream()
.collect(Collectors.groupingBy(TUser::getId, Collectors.toSet()));
看一些比较高级的功能:
List<TUser> users = Arrays.asList(
new TUser(1L, "Alice"),
new TUser(2L, "Bob"),
new TUser(1L, "Charlie"),
new TUser(2L, "David")
);
// 统计每个ID的数量
Map<Long, Long> countById = users.stream()
.collect(Collectors.groupingBy(TUser::getId, Collectors.counting()));
// 收集每个ID组的统计信息
Map<Long, LongSummaryStatistics> statsById = users.stream()
.collect(Collectors.groupingBy(
TUser::getId,
Collectors.summarizingLong(u -> u.getName().length())
));
// 将每个ID组的名字连接起来
Map<Long, String> namesByIdJoined = users.stream()
.collect(Collectors.groupingBy(
TUser::getId,
Collectors.mapping(TUser::getName, Collectors.joining(", "))
));
Collectors还有很多有用的方法,感兴趣可以自己试验一下。
分片的例子:
List<TUser> users = Arrays.asList(
new TUser(1L, "Alice"),
new TUser(2L, "Bob"),
new TUser(3L, "Admin"),
new TUser(4L, "User")
);
// 根据条件分为两组:true和false
Map<Boolean, List<TUser>> partitioned = users.stream()
.collect(Collectors.partitioningBy(u -> u.getName().startsWith("A")));
System.out.println("以A开头的用户: " + partitioned.get(true));
System.out.println("不以A开头的用户: " + partitioned.get(false));
# 10、原始类型流
Java 8为常用的原始类型提供了专门的Stream类,避免了装箱拆箱的性能损耗。主要有IntStream、LongStream和DoubleStream。以IntStream为例:
// 创建IntStream
IntStream stream1 = IntStream.of(1, 2, 3, 4, 5);
IntStream stream2 = Arrays.stream(new int[] {1, 2, 3}, 0, 2); // 从数组创建,指定范围
// 生成范围数值
List<String> numbers = IntStream.range(0, 10) // 0到9,不包括10
.mapToObj(String::valueOf)
.collect(Collectors.toList());
List<String> numbersInclusive = IntStream.rangeClosed(0, 10) // 0到10,包括10
.mapToObj(String::valueOf)
.collect(Collectors.toList());
// 装箱操作:原始类型流转换为对象流
Stream<Integer> boxedStream = IntStream.range(0, 100).boxed();
// IntStream特有的统计方法
IntStream numbers2 = IntStream.of(1, 2, 3, 4, 5);
System.out.println("总和: " + numbers2.sum());
numbers2 = IntStream.of(1, 2, 3, 4, 5);
System.out.println("平均值: " + numbers2.average().orElse(0));
# 11、并行流
并行流可以利用多核CPU提高处理性能。当计算stream.map(fun)时,流被分成多个子任务并发执行:
// 创建并行流的两种方式
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
numbers.parallelStream()
.filter(n -> n % 2 == 0)
.map(n -> n * n)
.forEach(System.out::println);
// 或者将串行流转换为并行流
Stream<Integer> parallelStream = numbers.stream().parallel();
并行流的最佳实践:
- 数据量较大时(通常超过1万个元素)才考虑使用并行流
- 每个元素的处理成本较高时更适合并行化
- 避免在并行流中使用有状态的操作
调整并行线程池大小:
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "16");
// 默认值为Runtime.getRuntime().availableProcessors()
# 三、新时间API
在Java 8之前,Java的日期时间处理一直是开发者的痛点。旧的Date和Calendar API设计混乱、线程不安全,导致许多项目不得不引入Joda-Time等第三方库。
Java 8的新时间API基于Joda-Time的设计理念,提供了全新的java.time包。这些新API具有以下优点:
- 不可变性:所有时间类都是不可变的,线程安全
- 清晰的API设计:方法名称和功能一目了然
- 强大的功能:支持时区、时期计算、格式化等
# 1、对日期进行加减
Java 8中提供了LocalDate、LocalTime和LocalDateTime分别表示日期、时间和日期时间。LocalDate的格式如2018-05-22,LocalTime的格式如15:49:50.494,那么LocalDateTime就是它们的结合体了。
直接看LocalDateTime的例子吧:
LocalDateTime dateTime = LocalDateTime.now();
// 日期加减操作(返回新对象,原对象不变)
LocalDateTime threeDaysLater = dateTime.plusDays(3); // 三天之后
LocalDateTime threeMonthsAgo = dateTime.minusMonths(3); // 三月之前
// 获取日期时间的各个部分
DayOfWeek dayOfWeek = dateTime.getDayOfWeek(); // 星期几
int dayOfMonth = dateTime.getDayOfMonth(); // 月份中的第几天
int second = dateTime.getSecond(); // 秒值
// 设置特定时间
LocalDateTime startOfDay = dateTime.with(LocalTime.MIN); // 今天的开始时间(00:00:00)
LocalDateTime endOfDay = dateTime.with(LocalTime.MAX); // 今天的结束时间(23:59:59.999999999)
// 链式调用
LocalDateTime result = dateTime
.plusDays(2)
.minusHours(3)
.withMinute(30);
plus系列方法用于相加,minus系列方法用于相减,get系列方法用于获得值,with系列方法用于获得处理后的副本。
# 2、日期的格式化
旧的SimpleDateFormat类是线程不安全的,在多线程环境下会出现问题。新的DateTimeFormatter是线程安全且不可变的:
// 解析日期字符串
LocalDate date = LocalDate.parse("2024-12-03", DateTimeFormatter.ofPattern("yyyy-MM-dd"));
LocalDateTime dateTime = LocalDateTime.parse("2024-12-03 10:15:30",
DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
// 格式化日期
String formattedDate = dateTime.format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
// 使用预定义格式
String isoDate = dateTime.format(DateTimeFormatter.ISO_LOCAL_DATE_TIME);
// 自定义格式并支持本地化
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy年MM月dd日 HH:mm:ss")
.withLocale(Locale.CHINA);
String chineseDate = dateTime.format(formatter);
# 3、对两个日期的判断和运算
判断两个日期:
LocalDateTime dateTime1 = LocalDateTime.of(2024, 1, 1, 10, 0);
LocalDateTime dateTime2 = LocalDateTime.of(2024, 1, 2, 10, 0);
boolean isAfter = dateTime2.isAfter(dateTime1); // true
boolean isBefore = dateTime1.isBefore(dateTime2); // true
boolean isEqual = dateTime1.equals(dateTime2); // false
// 比较日期部分(忽略时间)
boolean sameDate = dateTime1.toLocalDate().equals(dateTime2.toLocalDate());
计算两个日期之间相差的情况:
LocalDate startDate = LocalDate.of(2024, 1, 1);
LocalDate endDate = LocalDate.of(2024, 3, 15);
Period period = Period.between(startDate, endDate);
System.out.println("相差: " +
period.getYears() + "年 " +
period.getMonths() + "月 " +
period.getDays() + "天"); // 输出: 相差: 0年 2月 14天
// 获取总天数
long totalDays = ChronoUnit.DAYS.between(startDate, endDate);
System.out.println("总天数: " + totalDays);
Period和Duration的区别:
- Period:用于计算日期之间的差值(年、月、日)
- Duration:用于计算时间之间的差值(时、分、秒、纳秒)
// 使用Duration计算时间差
LocalDateTime start = LocalDateTime.of(2024, 1, 1, 10, 0);
LocalDateTime end = LocalDateTime.of(2024, 1, 1, 15, 30);
Duration duration = Duration.between(start, end);
System.out.println("时间差:" + duration.toHours() + "小时" +
(duration.toMinutes() % 60) + "分钟");
# 4、带时区的日期
语言对时区的支持,主要体现在UTC时间的转换上。这里需要注意一下,时区的名词有UTC和GMT,简单理解它们其实表示一个意思。
比如现在我想知道纽约现在是几点,一种方式是:
// 获取纽约时间
ZoneId newYorkZone = ZoneId.of("America/New_York");
LocalDateTime localDateTime = LocalDateTime.now();
ZonedDateTime newYorkTime = ZonedDateTime.of(localDateTime, newYorkZone);
System.out.println("本地时间: " + localDateTime);
System.out.println("纽约时间: " + newYorkTime);
// 更实用的方式:直接获取指定时区的当前时间
ZonedDateTime tokyoTime = ZonedDateTime.now(ZoneId.of("Asia/Tokyo"));
ZonedDateTime londonTime = ZonedDateTime.now(ZoneId.of("Europe/London"));
System.out.println("东京时间: " + tokyoTime.toLocalDateTime());
System.out.println("伦敦时间: " + londonTime.toLocalDateTime());
ZonedDateTime用于处理带时区的日期。
这里的ZoneId一定要写对,否则会抛异常。
还有另一种方式,用时区偏移量也可以实现时区时间转换:
// 使用时区偏移量
LocalDateTime datetime = LocalDateTime.now();
ZoneOffset offset = ZoneOffset.of("+08:00"); // 中国时区
OffsetDateTime offsetDateTime = OffsetDateTime.of(datetime, offset);
System.out.println("带偏移量的时间: " + offsetDateTime);
// 转换为UTC时间
OffsetDateTime utcTime = offsetDateTime.withOffsetSameInstant(ZoneOffset.UTC);
System.out.println("UTC时间: " + utcTime);
// 获取系统默认时区偏移
ZoneOffset systemOffset = OffsetDateTime.now().getOffset();
System.out.println("系统时区偏移: " + systemOffset);
这种方式对机器友好,第一种方式对人类友好。
# 5、与旧API的相互操作
Java 8中用Instant表示时间轴上的一个点,和原先的Date很像。
下面是Date、Instant和LocalDateTime之间的相互转换:
// Date 转 LocalDateTime
Date oldDate = new Date();
Instant instant = oldDate.toInstant();
LocalDateTime localDateTime = LocalDateTime.ofInstant(instant, ZoneId.systemDefault());
// 另一种方式
LocalDateTime localDateTime2 = instant
.atZone(ZoneId.systemDefault())
.toLocalDateTime();
// LocalDateTime 转 Date
ZoneId zoneId = ZoneId.systemDefault();
LocalDateTime now = LocalDateTime.now();
ZonedDateTime zdt = now.atZone(zoneId);
Date newDate = Date.from(zdt.toInstant());
// LocalDate 转 Date
LocalDate localDate = LocalDate.now();
Date dateFromLocalDate = Date.from(
localDate.atStartOfDay(zoneId).toInstant()
);
// 简化的工具方法
public static Date toDate(LocalDateTime localDateTime) {
return Date.from(localDateTime.atZone(ZoneId.systemDefault()).toInstant());
}
public static LocalDateTime toLocalDateTime(Date date) {
return LocalDateTime.ofInstant(date.toInstant(), ZoneId.systemDefault());
}
LocalDate或LocalDateTime转换为时间戳,都要先转换为Instant:
// LocalDateTime 转时间戳
LocalDateTime localDateTime = LocalDateTime.now();
long timestamp = localDateTime
.atZone(ZoneId.systemDefault())
.toInstant()
.toEpochMilli();
// LocalDate 转时间戳
LocalDate localDate = LocalDate.now();
long dateTimestamp = localDate
.atStartOfDay(ZoneId.systemDefault())
.toInstant()
.toEpochMilli();
// 时间戳转 LocalDateTime
long millis = System.currentTimeMillis();
LocalDateTime dateTimeFromTimestamp = LocalDateTime.ofEpochSecond(
millis / 1000,
(int)(millis % 1000) * 1_000_000,
ZoneOffset.ofHours(8) // 中国时区 +8
);
// 更简单的方式
LocalDateTime dateTimeFromMillis = Instant.ofEpochMilli(millis)
.atZone(ZoneId.systemDefault())
.toLocalDateTime();
时间戳转换为LocalDateTime,同理,需要从Instant中来:
long millis = System.currentTimeMillis();
// 时间戳转 LocalDateTime
LocalDateTime localDateTime = LocalDateTime.ofInstant(
Instant.ofEpochMilli(millis),
ZoneId.systemDefault()
);
// 从 LocalDateTime 获取各个部分
LocalDate localDate = localDateTime.toLocalDate(); // 获取日期部分
LocalTime localTime = localDateTime.toLocalTime(); // 获取时间部分
int year = localDateTime.getYear();
Month month = localDateTime.getMonth();
int day = localDateTime.getDayOfMonth();
# 6、时间调整之TemporalAdjusters
比如我要获取这个月的最后一天,可以这么做:
LocalDate date = LocalDate.of(2024, 1, 15);
// 使用TemporalAdjusters进行日期调整
LocalDate lastDayOfMonth = date.with(TemporalAdjusters.lastDayOfMonth()); // 月末
LocalDate firstDayOfMonth = date.with(TemporalAdjusters.firstDayOfMonth()); // 月初
LocalDate firstDayOfNextMonth = date.with(TemporalAdjusters.firstDayOfNextMonth()); // 下月初
LocalDate nextMonday = date.with(TemporalAdjusters.next(DayOfWeek.MONDAY)); // 下个周一
System.out.println("当前日期: " + date);
System.out.println("月末: " + lastDayOfMonth);
System.out.println("月初: " + firstDayOfMonth);
System.out.println("下月初: " + firstDayOfNextMonth);
System.out.println("下个周一: " + nextMonday);
这里出现了TemporalAdjusters类,它包含的方法如下:
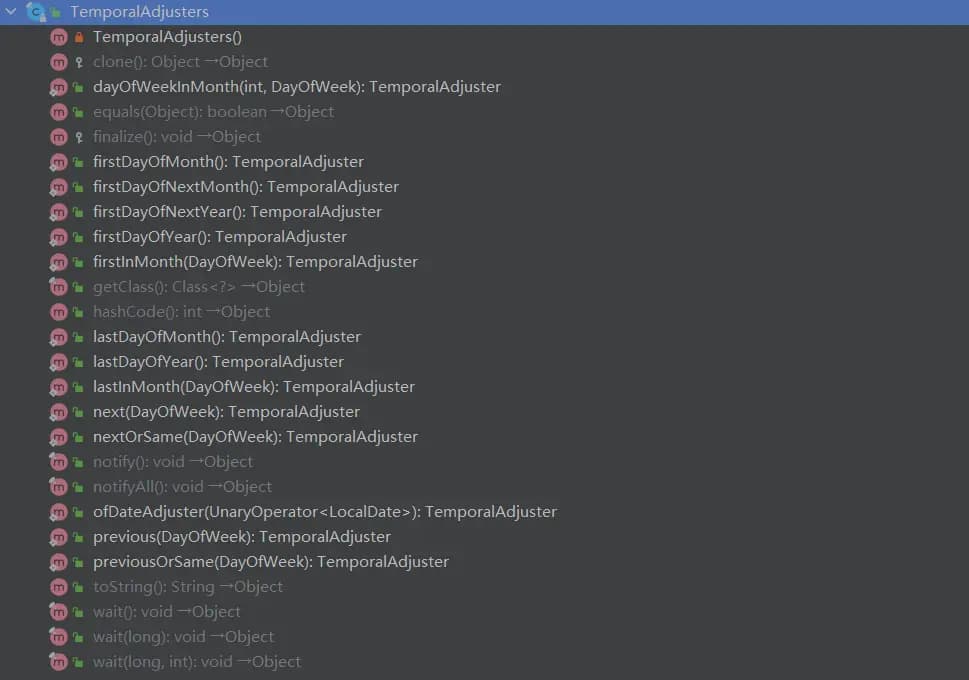
TemporalAdjusters其实是TemporalAdjuster的工具类,而TemporalAdjuster则是一个函数式接口,可以执行复杂的时间操作。
比如要获取某天之后的工作日:
// 自定义TemporalAdjuster:获取下一个工作日
public class WorkingDayAdjuster {
public static void main(String[] args) {
LocalDate date = LocalDate.of(2024, 7, 5); // 周五
LocalDate nextWorkingDay = date.with(NEXT_WORKING_DAY);
System.out.println("当前日期: " + date + " (" + date.getDayOfWeek() + ")");
System.out.println("下一个工作日: " + nextWorkingDay + " (" + nextWorkingDay.getDayOfWeek() + ")");
}
static TemporalAdjuster NEXT_WORKING_DAY = TemporalAdjusters.ofDateAdjuster(date -> {
DayOfWeek dayOfWeek = date.getDayOfWeek();
int daysToAdd;
if (dayOfWeek == DayOfWeek.FRIDAY) {
daysToAdd = 3; // 周五 -> 周一
} else if (dayOfWeek == DayOfWeek.SATURDAY) {
daysToAdd = 2; // 周六 -> 周一
} else {
daysToAdd = 1; // 其他 -> 下一天
}
return date.plusDays(daysToAdd);
});
}
# 总结
Java 8是Java发展史上的里程碑版本,它引入的Lambda表达式、Stream API和新时间API从根本上改变了Java的编程方式:
- Lambda表达式让Java支持函数式编程,代码更加简洁优雅
- Stream API提供了强大的数据处理能力,特别是在处理集合数据时
- 新时间API解决了旧API的各种问题,提供了线程安全、易用的日期时间处理方案
这些特性不仅提高了开发效率,还让Java代码更加现代化和易维护。作为Java开发者,深入掌握这些特性已经成为必备技能。
祝你变得更强!