 Java基准测试(JMH)
Java基准测试(JMH)
# 一、引言
# 1、为什么进行基准测试
在软件开发过程中,性能优化是很重要的一个环节。为了确保代码的性能达到预期,开发人员需要对不同的算法、数据结构以及系统配置进行比较。
基准测试是一种衡量程序性能的方法,通过对代码执行时间、吞吐量等指标的测量,可以为开发人员提供有关代码性能的可靠数据。
微基准测试的应用场景:
- 算法选择:比较不同排序算法、搜索算法的性能差异
- 数据结构对比:评估
ArrayListvsLinkedList、HashMapvsTreeMap的性能 - 框架选型:对比不同JSON解析库、序列化框架的处理速度
- 代码优化验证:验证性能优化措施是否真正有效
- JVM参数调优:测试不同JVM参数对性能的影响
# 2、什么是JMH
JMH(Java Microbenchmark Harness)是一个由OpenJDK团队开发的专门用于编写、运行和分析Java微基准测试的工具。
它提供了一套简单易用的API和注解,方便开发人员对Java代码进行性能评估。
JMH的核心优势:
- 消除JVM优化干扰:自动处理JIT编译、死代码消除等优化带来的测量偏差
- 统计学支持:提供标准差、置信区间等统计数据,确保结果可靠
- 多种测试模式:支持吞吐量、平均时间、采样等多种测量维度
- 并发测试支持:内置多线程测试能力,模拟真实并发场景
- 官方维护:由OpenJDK团队维护,与JVM发展同步
# 二、JMH基本概念
# 1、基准测试方法
基准测试方法是JMH用于衡量性能的核心代码。通常,一个基准测试方法应该只包含要评估性能的代码片段,以便更准确地测量执行时间。
基准测试方法的特点:
- 使用
@Benchmark注解标记 - 可以有参数(通过
@State注入) - 可以有返回值(返回值会被消费,避免死代码消除)
- 应该尽量简洁,只包含被测试的核心逻辑
# 2、基准测试模式
JMH提供了几种基准测试模式,用于衡量不同的性能指标:
Throughput:吞吐量模式,测量单位时间内的操作次数(ops/time)
- 适用场景:批处理任务、消息队列处理
- 输出示例:
200000 ops/s
AverageTime:平均时间模式,测量每个操作的平均执行时间
- 适用场景:API响应时间、数据库查询
- 输出示例:
5.2 ms/op
SampleTime:采样时间模式,随机采样操作的执行时间分布
- 适用场景:需要了解性能分布、找出异常值
- 输出示例:
p0.50: 1.2ms, p0.99: 5.3ms, p0.999: 12.1ms
SingleShotTime:单次执行时间,测量冷启动性能
- 适用场景:启动性能测试、首次加载测试
- 输出示例:
100 ms/op
All:运行所有模式,获取全面的性能数据
# 3、Warm-up(预热)
JVM在运行过程中会对代码进行即时编译(JIT)优化。为了避免JIT对基准测试结果的影响,JMH提供了预热(Warm-up)机制。
预热的重要性:
- JIT编译优化:让热点代码完成C1、C2编译优化
- 类加载完成:确保所有需要的类已经加载
- 内存分配稳定:让JVM内存分配达到稳定状态
- 缓存预热:CPU缓存、分支预测器等硬件优化生效
预热参数配置:
@Warmup(iterations = 3, time = 1, timeUnit = TimeUnit.SECONDS)
// iterations: 预热轮数
// time: 每轮预热时间
// timeUnit: 时间单位
# 4、测量单位
JMH支持多种时间单位,选择合适的单位可以让结果更易读:
| 时间单位 | 缩写 | 适用场景 |
|---|---|---|
NANOSECONDS | ns | CPU指令级操作、内存访问 |
MICROSECONDS | μs | 简单算法、集合操作 |
MILLISECONDS | ms | 复杂算法、IO操作 |
SECONDS | s | 批处理、网络请求 |
选择原则:让结果数值在1-1000之间,便于阅读和比较。
# 5、并发控制
JMH允许通过设置线程数、调用线程组等方式对基准测试的并发性进行控制:
@Threads:指定并发线程数@Threads(4) // 使用4个线程并发执行 @Threads(Threads.MAX) // 使用CPU核心数@Group和@GroupThreads:线程组控制@Group("readWrite") @GroupThreads(3) @Benchmark public void read() { } @Group("readWrite") @GroupThreads(1) @Benchmark public void write() { }
这可以帮助开发人员评估代码在不同并发场景下的性能表现。
# 三、JMH环境搭建
# 1、生成JMH项目
根据官网 (opens new window)步骤,使用下面命令生成示例项目:
在pom.xml文件中添加以下依赖:
mvn archetype:generate \
-DinteractiveMode=false \
-DarchetypeGroupId=org.openjdk.jmh \
-DarchetypeArtifactId=jmh-java-benchmark-archetype \
-DgroupId=org.sample \
-DartifactId=jmh-demo \
-Dversion=1.0
# 2、配置JMH插件
生成的项目,pom.xml中配置如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.sample</groupId>
<artifactId>test</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<name>Auto-generated JMH benchmark</name>
<prerequisites>
<maven>3.0</maven>
</prerequisites>
<dependencies>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>${jmh.version}</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>${jmh.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<jmh.version>1.36</jmh.version>
<javac.target>11</javac.target>
<uberjar.name>benchmarks</uberjar.name>
</properties>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<compilerVersion>${javac.target}</compilerVersion>
<source>${javac.target}</source>
<target>${javac.target}</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.2</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<finalName>${uberjar.name}</finalName>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>org.openjdk.jmh.Main</mainClass>
</transformer>
</transformers>
<filters>
<filter>
<!--
Shading signed JARs will fail without this.
http://stackoverflow.com/questions/999489/invalid-signature-file-when-attempting-to-run-a-jar
-->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Maven Shade插件用于打包可执行JAR文件。
这里将JMH运行时库和测试类打包到同一个JAR文件中。
- goals指定了Shade插件执行的目标,这里是shade。
- finalName指定了生成的JAR文件名称。
- transformers指定了Shade插件的转换器,这里使用了ManifestResourceTransformer,将JMH的Main类设置为可执行JAR文件的主类。
- filters指定了Shade插件的过滤器,用于过滤掉JAR文件中的签名文件。这是为了解决在将已签名的JAR文件打包到Shade JAR文件中时可能出现的问题。
# 3、编写基准测试代码
示例项目中有MyBenchmark类,我们来补充一下:
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.infra.Blackhole;
import java.util.concurrent.TimeUnit;
import java.util.Random;
@State(Scope.Thread)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@Warmup(iterations = 3, time = 1, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Fork(1)
public class MyBenchmark {
@Param({"100", "200", "300"})
private int length;
private int[] array;
@Setup
public void setUp() {
array = new int[length];
Random random = new Random();
for (int i = 0; i < length; i++) {
array[i] = random.nextInt();
}
}
@Benchmark
public void testBubbleSort(Blackhole bh) {
int[] sortedArray = bubbleSort(array.clone());
bh.consume(sortedArray);
}
@Benchmark
public void testQuickSort(Blackhole bh) {
int[] sortedArray = quickSort(array.clone(), 0, array.length - 1);
bh.consume(sortedArray);
}
public int[] bubbleSort(int[] array) {
int n = array.length;
boolean swapped;
for (int i = 0; i < n - 1; i++) {
swapped = false;
for (int j = 0; j < n - 1 - i; j++) {
if (array[j] > array[j + 1]) {
int temp = array[j];
array[j] = array[j + 1];
array[j + 1] = temp;
swapped = true;
}
}
if (!swapped) {
break;
}
}
return array;
}
public int[] quickSort(int[] array, int low, int high) {
if (low < high) {
int pivotIndex = partition(array, low, high);
quickSort(array, low, pivotIndex - 1);
quickSort(array, pivotIndex + 1, high);
}
return array;
}
private int partition(int[] array, int low, int high) {
int pivot = array[high];
int i = low - 1;
for (int j = low; j < high; j++) {
if (array[j] <= pivot) {
i++;
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
}
int temp = array[i + 1];
array[i + 1] = array[high];
array[high] = temp;
return i + 1;
}
@TearDown
public void tearDown() {
array = null;
}
}
# 4、运行基准测试
在命令行中执行以下命令运行基准测试:
mvn clean verify
java -jar target/benchmarks.jar
还可以允许java -jar target/benchmarks.jar -h来查看帮助。
# 四、JMH注解详解
# 1、@Benchmark
@Benchmark注解用于标记基准测试方法。JMH会自动扫描并执行所有带有此注解的方法。
# 2、@Fork
@Fork注解用于指定基准测试的进程数。每个进程将独立运行基准测试,以减小JVM参数和垃圾回收对测试结果的影响。默认值为1。
# 3、@Warmup
@Warmup注解用于设置预热参数。可以指定预热的迭代次数(iterations)和每次迭代的时间(time)。
# 4、@Measurement
@Measurement注解用于设置正式测量的参数。可以指定正式测量的迭代次数(iterations)和每次迭代的时间(time)。
# 5、@BenchmarkMode
@BenchmarkMode注解用于设置基准测试模式。可以使用一个或多个模式。
JMH提供了多种基准模式,每种模式都有不同的测试策略和输出格式。以下是JMH支持的基准模式:
Throughput:测试方法的吞吐量,即每秒执行的操作次数。AverageTime:测试方法的平均执行时间。SampleTime:测试方法的随机取样时间,即对方法进行多次执行,并对执行时间进行采样。SingleShotTime:测试方法的单次执行时间,即只执行一次方法,并测量执行时间。All:同时运行所有的基准模式,并将结果输出到单个文件中。
# 6、@OutputTimeUnit
@OutputTimeUnit注解用于指定基准测试结果的时间单位。支持的单位包括纳秒(NANOSECONDS)、微秒(MICROSECONDS)、毫秒(MILLISECONDS)和秒(SECONDS)。
# 7、@State
State 用于声明某个类是一个”状态”,然后接受一个 Scope 参数用来表示该状态的共享范围。
因为很多 benchmark 会需要一些表示状态的类,JMH 允许你把这些类以依赖注入的方式注入到 benchmark 函数里。
支持的范围包括:
Benchmark所有线程共享Group同一组现场共享Thread每个线程独享
可以将此注解应用于包含共享资源的类上。
# 8、@Param
@Param注解用于为基准测试方法提供输入参数。可以将此注解应用于共享资源类的字段上,然后在基准测试方法中使用这些字段。
# 9、@Setup
@Setup注解用于标记资源初始化方法。此方法将在基准测试开始之前执行。
# 10、@TearDown
@TearDown注解用于标记资源释放方法。此方法将在基准测试结束后执行。
# 11、@Threads
@Threads 用于指定测试方法运行的线程数。JMH可以通过多线程并发地运行测试方法来模拟实际应用程序中的并发场景。
有些注解理解起来比较困难,可以参考:官方示例 (opens new window)
# 五、JMH高级功能
# 1、使用Profiler分析性能瓶颈
JMH支持使用Profiler对基准测试进行性能分析。可以通过命令行参数-prof指定要使用的Profiler,例如:
java -jar target/benchmarks.jar -prof comp -prof cl
关于可用的Profiler,可以使用java -jar target/benchmarks.jar -lprof查看。
以Java 11为例,可用的Profiler有:
cl:表示启用Classloader分析器,用于分析类加载行为。comp:表示启用JIT编译器分析器,用于分析编译器行为。gc:表示启用垃圾回收分析器,用于分析GC行为。jfr:表示启用Java Flight Recorder分析器,用于记录应用程序的运行情况和事件。pauses:表示启用暂停分析器,用于分析应用程序中的暂停情况。perfc2c:表示启用Linux perf c2c分析器,用于分析CPU缓存行的使用情况。safepoints:表示启用安全点分析器,用于分析应用程序中的安全点情况。stack:表示启用堆栈跟踪分析器,用于分析应用程序中的函数调用和返回情况。
# 2、自定义Benchmark运行器
通过org.openjdk.jmh.runner.Runner类,可以创建自定义的基准测试运行器。这可以用于在运行基准测试时自定义JMH的行为。
以下是一个示例,演示如何使用Options类自定义Benchmark运行器:
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import org.openjdk.jmh.runner.options.TimeValue;
@State(Scope.Benchmark)
public class MyBenchmark {
@Benchmark
public void testMethod() {
// Your benchmark method here
}
public static void main(String[] args) throws Exception {
Options options = new OptionsBuilder()
.include(MyBenchmark.class.getSimpleName())
.warmupTime(TimeValue.seconds(1))
.measurementTime(TimeValue.seconds(5))
.forks(1)
.build();
new Runner(options).run();
}
}
在上面的示例中,我们定义了一个名为MyBenchmark的类,并在其中定义了一个名为testMethod的基准方法。然后,我们在main方法中使用OptionsBuilder类创建一个Options对象,用于指定Benchmark运行的参数和选项。具体来说,我们使用以下方法设置了一些常用的选项:
include方法:指定要运行的Benchmark类。在本例中,我们使用MyBenchmark.class.getSimpleName()获取类的简单名称,并将其传递给include方法。warmupTime方法:指定Benchmark的预热时间。在本例中,我们使用TimeValue.seconds(1)指定预热时间为1秒。measurementTime方法:指定Benchmark的测量时间。在本例中,我们使用TimeValue.seconds(5)指定测量时间为5秒。forks方法:指定要运行Benchmark的次数。在本例中,我们使用forks(1)指定只运行一次。
最后,我们使用Runner类运行Benchmark,并将上面创建的Options对象作为参数传递给它。这将启动Benchmark运行器,并运行指定的Benchmark类。
如果你执行Runner的时候报错:
ERROR: transport error 202: connect failed: Connection refused你需要检查hosts文件,让127.0.0.1和localhost对应
# 3、结果导出与报告生成
JMH允许将基准测试结果导出为JSON、CSV和XML格式。可以通过命令行参数-lrf查看支持的输出格式。可以通过-rf和-rff设置输出格式和文件名。
比如:java -jar target/benchmarks.jar -rf json -rff result.json
此外,可以使用第三方工具JMH Visualizer (opens new window)将导出的结果转换为图形报告。
# 4、IDEA的JMH插件
上面的步骤还是略显麻烦,在IDEA中安装JMH Java Microbenchmark Harness (opens new window)插件可以提高JMH测试的效率。
# 5、微基准测试策略
在编写微基准测试时,需要注意以下几点:
- 确保基准测试方法足够简单,只包含要测量性能的代码片段。
- 使用合适的预热策略,以减小JIT优化对测试结果的影响。
- 选择合适的测试模式、时间单位和并发控制参数。
# 六、JMH实践案例
# 1、字符串拼接性能对比
对比不同字符串拼接方式的性能差异:
@State(Scope.Thread)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@Warmup(iterations = 3, time = 1)
@Measurement(iterations = 5, time = 1)
@Fork(1)
public class StringConcatBenchmark {
@Param({"10", "100", "1000"})
private int iterations;
@Benchmark
public String testStringBuilder() {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < iterations; i++) {
sb.append("string").append(i);
}
return sb.toString();
}
@Benchmark
public String testStringBuffer() {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < iterations; i++) {
sb.append("string").append(i);
}
return sb.toString();
}
@Benchmark
public String testStringConcat() {
String result = "";
for (int i = 0; i < iterations; i++) {
result = result + "string" + i; // 性能最差
}
return result;
}
}
典型结果分析:
StringBuilder:最快,非线程安全StringBuffer:较慢,线程安全- 字符串直接拼接:最慢,每次创建新对象
# 2、集合遍历性能测试
@State(Scope.Benchmark)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
public class CollectionIterationBenchmark {
@Param({"1000", "10000", "100000"})
private int size;
private List<Integer> arrayList;
private List<Integer> linkedList;
@Setup
public void setup() {
arrayList = new ArrayList<>(size);
linkedList = new LinkedList<>();
for (int i = 0; i < size; i++) {
arrayList.add(i);
linkedList.add(i);
}
}
@Benchmark
public int arrayListFor() {
int sum = 0;
for (int i = 0; i < arrayList.size(); i++) {
sum += arrayList.get(i);
}
return sum;
}
@Benchmark
public int arrayListForEach() {
int sum = 0;
for (Integer value : arrayList) {
sum += value;
}
return sum;
}
@Benchmark
public int arrayListStream() {
return arrayList.stream()
.mapToInt(Integer::intValue)
.sum();
}
@Benchmark
public int linkedListFor() {
int sum = 0;
for (int i = 0; i < linkedList.size(); i++) {
sum += linkedList.get(i); // O(n)访问,性能极差
}
return sum;
}
@Benchmark
public int linkedListForEach() {
int sum = 0;
for (Integer value : linkedList) {
sum += value; // 使用迭代器,性能好
}
return sum;
}
}
# 3、对比不同算法的性能
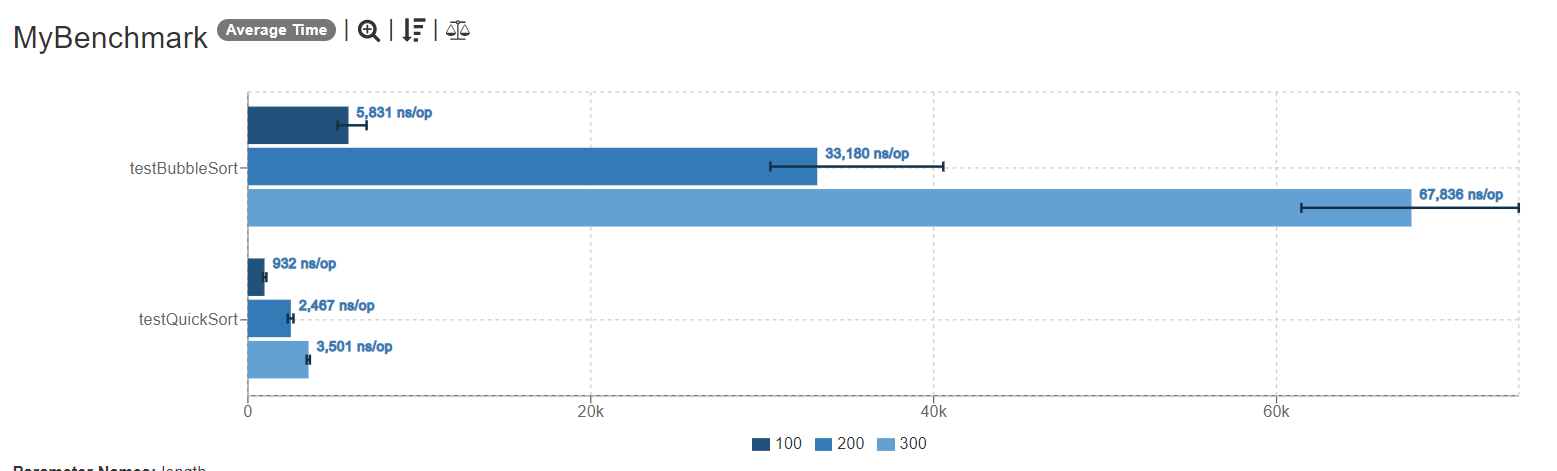
使用JMH可以帮助我们对比不同算法在相同输入条件下的性能表现。
在上面的示例中,我们就对冒泡排序和快速排序做了比较。
# 4、验证JVM参数对性能的影响
JMH可以用于验证JVM参数对程序性能的影响。通过 @Fork 注解配置不同的JVM参数:
@State(Scope.Benchmark)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public class JVMOptionsBenchmark {
@Benchmark
@Fork(value = 1, jvmArgs = {"-Xms1G", "-Xmx1G"})
public void smallHeap() {
allocateMemory();
}
@Benchmark
@Fork(value = 1, jvmArgs = {"-Xms4G", "-Xmx4G"})
public void largeHeap() {
allocateMemory();
}
@Benchmark
@Fork(value = 1, jvmArgs = {"-XX:+UseG1GC"})
public void withG1GC() {
allocateMemory();
}
@Benchmark
@Fork(value = 1, jvmArgs = {"-XX:+UseParallelGC"})
public void withParallelGC() {
allocateMemory();
}
private void allocateMemory() {
List<byte[]> list = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
list.add(new byte[1024 * 1024]); // 分配1MB
}
}
}
# 5、并发容器性能测试
JMH可以用于评估并发容器(如java.util.concurrent包中的类)在不同并发场景下的性能。
例如,我们可以编写一个基准测试,对比ConcurrentHashMap和Hashtable在多线程环境下的性能表现。
import org.openjdk.jmh.annotations.*;
import java.util.Hashtable;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ThreadLocalRandom;
import java.util.concurrent.TimeUnit;
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@State(Scope.Benchmark)
@Warmup(iterations = 2, time = 1, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Fork(1)
public class MapBenchmark {
private static final int THREAD_COUNT = 4;
private static final int ELEMENT_COUNT = 100000;
private Map<Integer, Integer> concurrentHashMap;
private Map<Integer, Integer> hashtable;
@Setup
@Threads(THREAD_COUNT)
public void setup() {
concurrentHashMap = new ConcurrentHashMap<>();
hashtable = new Hashtable<>();
}
@Benchmark
@Threads(THREAD_COUNT)
public void testConcurrentHashMap() {
ThreadLocalRandom random = ThreadLocalRandom.current();
for (int i = 0; i < ELEMENT_COUNT; i++) {
concurrentHashMap.put(random.nextInt(), random.nextInt());
}
}
@Benchmark
public void testHashtable() {
ThreadLocalRandom random = ThreadLocalRandom.current();
for (int i = 0; i < ELEMENT_COUNT; i++) {
hashtable.put(random.nextInt(), random.nextInt());
}
}
}
# 6、Java Stream API性能测试
JMH还可以用于评估Java Stream API在不同场景下的性能。
例如,我们可以编写一个基准测试,对比使用Stream API和传统的for循环遍历集合的性能。
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@Warmup(iterations = 3, time = 1)
@Measurement(iterations = 5, time = 1)
@Fork(1)
public class StreamVsForLoopBenchmark {
@State(Scope.Benchmark)
public static class BenchmarkState {
public List<Integer> list;
@Setup(Level.Trial)
public void setUp() {
list = new ArrayList<>();
for (int i = 0; i < 100000; i++) {
list.add(i);
}
}
}
@Benchmark
public List<Integer> testStreamAPI(BenchmarkState state) {
return state.list.stream()
.filter(i -> i % 2 == 0)
.collect(Collectors.toList());
}
@Benchmark
public List<Integer> testForLoop(BenchmarkState state) {
List<Integer> evenNumbers = new ArrayList<>();
for (Integer i : state.list) {
if (i % 2 == 0) {
evenNumbers.add(i);
}
}
return evenNumbers;
}
public static void main(String[] args) throws RunnerException {
Options options = new OptionsBuilder()
.include(StreamVsForLoopBenchmark.class.getSimpleName())
.build();
new Runner(options).run();
}
}
# 七、常见陷阱与解决方案
# 1、循环优化陷阱
JVM可能会优化掉看似有用但实际无效的循环:
// 错误示例 - 循环可能被优化掉
@Benchmark
public void wrongLoop() {
for (int i = 0; i < 1000; i++) {
Math.sqrt(i); // 结果未使用,可能被优化掉
}
}
// 正确示例 - 使用Blackhole消费结果
@Benchmark
public void correctLoop(Blackhole bh) {
for (int i = 0; i < 1000; i++) {
bh.consume(Math.sqrt(i));
}
}
# 2、常量折叠陷阱
编译器会在编译时计算常量表达式:
// 错误示例 - 编译时计算
@Benchmark
public int constantFolding() {
return 2 * 3 * 4 * 5; // 编译时变为 return 120;
}
// 正确示例 - 使用@State注入变量
@State(Scope.Benchmark)
public static class MyState {
public int a = 2, b = 3, c = 4, d = 5;
}
@Benchmark
public int avoidConstantFolding(MyState state) {
return state.a * state.b * state.c * state.d;
}
# 3、伪共享问题
多线程测试时,CPU缓存行的伪共享会严重影响性能:
// 可能存在伪共享的示例
@State(Scope.Group)
public class SharedState {
public volatile long x;
public volatile long y; // 可能与x在同一缓存行
}
// 使用填充避免伪共享
@State(Scope.Group)
public class PaddedState {
public volatile long x;
public long p1, p2, p3, p4, p5, p6, p7; // 缓存行填充
public volatile long y; // 确保在不同缓存行
}
# 八、注意事项与最佳实践
# 1、避免死代码消除
为了确保基准测试方法的执行不会被JVM优化器消除,可以使用org.openjdk.jmh.infra.Blackhole类消费测试方法的返回值。这可以防止JVM将没有实际作用的代码优化掉。
import org.openjdk.jmh.annotations.*;
@State(Scope.Thread)
public class OptimizedBenchmark {
private static final int ARRAY_SIZE = 1000;
@Benchmark
public void testMethod() {
int[] array = new int[ARRAY_SIZE];
for (int i = 0; i < ARRAY_SIZE; i++) {
array[i] = i;
}
// 注意这里没有返回值,也没有使用 Blackhole 消费中间结果
}
}
JVM 优化器可能会认为这段代码没有实际作用,因为数组并没有被使用或返回。因此,JVM 优化器可能会删除这段代码或者将其替换为更简单的实现,从而导致基准测试的结果不真实地高。
可以使用Blackhole类消费计算结果,以避免JVM对未使用结果的代码进行优化。例如:
@Benchmark
public void testMethod(Blackhole bh) {
...
bh.consume(array);
}
关于JVM优化技术,参考:深入理解JIT编译器
# 2、使用正确的测试范围
为了获得准确的测试结果,请确保在基准测试方法中使用正确的测试范围。例如,在对比两个算法时,应确保它们处理相同的输入数据。
# 3、多次运行测试以提高可靠性
为了确保基准测试结果的可靠性,建议多次运行测试并分析结果。这有助于发现潜在的性能问题和异常值。
# 4、基准测试调试技巧
当基准测试结果不符合预期时,可以使用以下调试技巧:
@State(Scope.Thread)
public class DebugBenchmark {
// 使用-prof perfnorm查看更详细的性能数据
@Benchmark
@CompilerControl(CompilerControl.Mode.DONT_INLINE) // 防止内联
public void debugMethod() {
// 测试代码
}
// 打印编译日志
@Fork(jvmArgs = {"-XX:+PrintCompilation"})
@Benchmark
public void withCompilationLog() {
// 查看JIT编译过程
}
// 使用断言验证正确性
@Benchmark
public int withAssertion() {
int result = complexCalculation();
assert result > 0 : "Result should be positive";
return result;
}
}
常用调试参数:
-prof perfnorm:显示每个操作的指令数和CPU周期-prof gc:显示GC统计信息-prof stack:显示热点方法的调用栈-v EXTRA:显示更详细的执行信息
# 九、性能测试检查清单
在进行JMH基准测试时,使用以下检查清单确保测试质量:
✅ 测试设计
- [ ] 测试方法是否足够简单,只包含核心逻辑?
- [ ] 是否使用了
@State正确管理测试状态? - [ ] 是否选择了合适的
@BenchmarkMode? - [ ] 时间单位是否合理(结果在1-1000之间)?
✅ 避免优化陷阱
- [ ] 是否使用
Blackhole消费无用结果? - [ ] 是否避免了常量折叠?
- [ ] 循环是否可能被优化掉?
- [ ] 多线程测试是否考虑了伪共享?
✅ 测试配置
- [ ] 预热次数是否足够(通常3-5次)?
- [ ] 测量次数是否足够(通常5-10次)?
- [ ]
@Fork数量是否合理(至少1次)? - [ ] 是否需要设置特定的JVM参数?
✅ 结果分析
- [ ] 是否关注了标准差和置信区间?
- [ ] 是否对比了不同参数下的结果?
- [ ] 是否验证了测试的可重复性?
- [ ] 是否使用Profiler分析了性能瓶颈?
# 十、结论
JMH是Java性能测试的黄金标准,它不仅是一个工具,更是一套科学的性能测试方法论。通过本文的学习,你应该掌握了:
# 1、核心知识点回顾
- 基础概念:理解预热、测试模式、并发控制等核心概念
- 注解使用:熟练运用
@Benchmark、@State、@Setup等注解 - 陷阱规避:识别并避免死代码消除、常量折叠、伪共享等优化陷阱
- 实践应用:通过实际案例掌握性能测试的设计和实施
# 2、进阶学习资源
- 📚 JMH官方示例 (opens new window):最权威的学习材料
- 📖 JMH源码 (opens new window):深入理解实现原理
- 🎯 JMH Visualizer (opens new window):可视化分析测试结果
- 💡 性能优化最佳实践 (opens new window):OpenJDK官方建议
# 3、最佳实践总结
- 先测量,后优化:不要凭感觉优化,用数据说话
- 隔离变量:每次只测试一个变化点
- 模拟真实场景:测试数据和并发度要贴近生产环境
- 持续监控:性能测试应该成为CI/CD的一部分
- 全面分析:不只看平均值,还要关注分布和异常值
记住,性能优化是一门艺术,需要在可读性、可维护性和性能之间找到平衡。JMH为我们提供了科学的测量手段,但最终的决策还需要结合具体的业务场景和需求。
"过早的优化是万恶之源" - Donald Knuth
但有了JMH,我们可以在正确的时间做正确的优化。
祝你变得更强!