 高可用-分布式基础之CAP理论
高可用-分布式基础之CAP理论
对于刚进入分布式领域的开发者来说,常会怀有一系列错误的假设。这些假设被称为分布式计算的八大谬误(Fallacies of Distributed Computing),由 Sun Microsystems 的工程师们在 1994-1997 年间总结出来:
- 网络是可靠的 - 实际上网络会出现故障、丢包、超时
- 延迟是零 - 网络传输必然存在延迟,从毫秒到秒级不等
- 带宽是无限的 - 带宽资源有限且昂贵
- 网络是安全的 - 需要考虑加密、认证、授权等安全措施
- 拓扑不会改变 - 网络拓扑会因节点增减、路由变化而改变
- 只有一个管理员 - 分布式系统涉及多个团队和管理域
- 传输成本是零 - 需要考虑带宽成本、序列化开销
- 网络是同构的 - 不同节点可能有不同的操作系统、协议和性能
而有了这些错误假定,就是系统设计悲剧的开始。
# 一、分布式系统的现实挑战
相应地,为了设计好一个分布式系统,你应该充分认识到以下现实:
- 网络不可靠 - 需要设计重试、超时、熔断等容错机制
- 延迟不可避免 - 需要异步处理、缓存、CDN 等优化策略
- 带宽是瓶颈 - 需要数据压缩、批处理、流控等优化
- 安全是必需的 - 需要 TLS/SSL、OAuth、防火墙等安全措施
- 拓扑会演化 - 需要服务发现、负载均衡、弹性伸缩
- 管理是分布式的 - 需要统一的监控、日志、配置管理
- 传输有成本 - 需要考虑数据本地化、边缘计算
- 异构是常态 - 需要标准化协议、中间件、适配层
# 二、CAP 理论的诞生背景
有了以上的现实挑战,可以想象设计一个好的分布式系统是非常困难的。当面对如此复杂的问题时,我们需要一个理论框架来指导系统设计。
这个理论框架就是 CAP 理论,由加州大学伯克利分校的 Eric Brewer 教授在 2000 年 ACM PODC 会议上提出。最初这只是一个猜想:
在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)三者不可兼得,最多只能同时满足其中两个。
2002 年,MIT 的 Seth Gilbert 和 Nancy Lynch 从理论上严格证明了 CAP 定理(原始论文 (opens new window))。
CAP 理论的核心价值:它明确告诉我们,在分布式环境中不存在完美的解决方案,系统设计必须在这三个属性之间做出权衡。
# 三、深入理解 CAP 三要素
# 1、一致性(Consistency)
一致性是指所有节点在同一时刻看到的数据是相同的。具体来说:
- 当一个节点更新数据后,所有节点都能立即看到这个更新
- 对客户端而言,无论连接到哪个节点,读取到的数据都是最新的
- 实现方式:通常采用同步复制,写操作需要等待所有副本确认后才返回成功
示例场景:银行转账系统,账户余额在所有节点上必须保持一致,避免重复扣款或余额不一致。
# 2、可用性(Availability)
可用性是指系统保持可操作状态,每个请求都能在合理时间内得到响应(不管是成功还是失败)。具体要求:
- 系统一直处于可服务状态
- 每个请求都能收到响应(非错误响应)
- 响应时间在可接受范围内
注意:这里的可用性不同于传统的高可用(99.99%),而是指非故障节点必须响应请求。
# 3、分区容错性(Partition Tolerance)
分区容错性是指系统能够容忍网络分区的发生。网络分区是指:
- 集群中的节点被分隔成多个区域
- 区域之间网络不通,但区域内部正常通信
- 常见原因:网络故障、交换机故障、数据中心间链路中断
重要观点:在分布式系统中,网络分区是不可避免的,因此 P 是必须保证的,实际选择是在 C 和 A 之间权衡。
用图片表示 CAP 的关系:
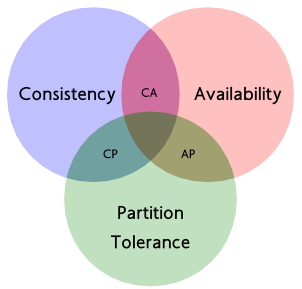
# 4、CAP 的数学定义
虽然不详细展开证明过程,但了解 CAP 的严格定义有助于深入理解:
- 一致性:对于所有的数据对象 x,如果在时间 t1 写入值 v,那么在 t1 之后的任何读操作都必须返回 v 或更新的值
- 可用性:对于任何非故障节点收到的请求,必须产生响应
- 分区容错:即使任意数量的消息被网络丢失或延迟,系统仍能继续运行
# 四、CAP 权衡策略详解
# 1、CA 系统:放弃分区容错性
选择 CA 意味着放弃分区容错性,这实际上意味着放弃了真正的分布式架构。
典型代表:
- 单机关系型数据库:如单节点的 MySQL、PostgreSQL
- 集群内共享存储:如传统的 SAN 存储架构
- 两阶段提交(2PC):在无网络分区时工作良好
局限性:
- 无法应对网络分区,一旦发生分区,系统将不可用
- 扩展性受限,难以横向扩展
- 不适合跨地域部署
重要观点:在真实的分布式环境中,网络分区是不可避免的,因此纯粹的 CA 系统实际上不是分布式系统。正如 CAP 理论的现代解释:"在分布式系统中,分区容错性是必须的,真正的选择是在一致性和可用性之间权衡。"
# 2、CP 系统:保证一致性和分区容错
选择 CP 意味着在网络分区时,宁可拒绝服务也要保证数据一致性。
适用场景:
- 金融交易系统:宁可暂停服务,也不能出现数据不一致
- 库存管理系统:防止超卖,保证库存数据准确
- 配置管理系统:确保配置的一致性,避免系统行为异常
典型代表:
- ZooKeeper:分布式协调服务,保证配置一致性
- HBase:强一致性的分布式存储
- MongoDB(主从模式):写操作需要多数节点确认
- Redis Cluster:在分区时部分 key 不可用
关键技术:
# 2.1、Paxos算法
Google 的 Chubby 锁服务的核心算法。Mike Burrows 曾说:"世界上只有一种一致性算法,就是 Paxos。"
核心思想:
- 基于多数派(Majority)的共识算法
- 分为两个阶段:准备阶段(Prepare)和接受阶段(Accept)
- 只要超过半数节点同意,提案就能通过
# 2.2、ZAB协议(ZooKeeper Atomic Broadcast)
ZooKeeper 实际使用的协议,是 Paxos 的一个变种:
- 崩溃恢复:Leader 选举,数据同步
- 消息广播:类似两阶段提交,但只需要半数以上 ACK
- 顺序保证:全局有序的 ZXID
# 2.3、Raft算法
为了解决 Paxos 难以理解的问题,Stanford 提出了 Raft:
- Leader 选举:通过随机超时避免选票分裂
- 日志复制:Leader 负责日志复制到 Follower
- 安全性:确保已提交的日志不会丢失
优化策略:
- 读写分离:读操作可以从 Follower 节点读取
- 多数派写入:不需要所有节点都写入成功
- 租约机制:在租约期内保证一致性,提高读性能
# 3、AP 系统:保证可用性和分区容错
选择 AP 意味着接受数据的不一致,以换取系统的高可用性。
适用场景:
- 社交网络:点赞数、评论数可以短暂不一致
- 电商推荐:商品推荐可以基于稍旧的数据
- DNS 系统:域名解析可以返回缓存数据
典型代表:
- Cassandra:最终一致性的分布式数据库
- DynamoDB:Amazon 的 NoSQL 数据库
- Eureka:Netflix 的服务发现组件
- CouchDB:文档型数据库,支持多主复制
# 4、一致性模型的细分
CAP 中的一致性是指强一致性,但实际系统中存在多种一致性级别:
| 一致性级别 | 描述 | 应用场景 | 实现难度 |
|---|---|---|---|
| 强一致性 | 所有节点同时看到相同数据 | 金融交易、库存 | 高 |
| 顺序一致性 | 所有节点看到相同的操作顺序 | 分布式锁 | 较高 |
| 因果一致性 | 有因果关系的操作保持顺序 | 社交评论回复 | 中 |
| 最终一致性 | 最终所有节点数据相同 | 缓存、CDN | 低 |
| 弱一致性 | 不保证何时达到一致 | 实时性要求不高的统计 | 最低 |
# 五、BASE 理论:CAP 的工程实践
# 1、BASE 理论概述
BASE 是对 CAP 中 AP 方案的一个补充,由 eBay 架构师 Dan Pritchett 提出:
- Basically Available(基本可用)
- Soft state(软状态)
- Eventually consistent(最终一致性)
核心思想:既然无法做到强一致性,那就根据业务特点,采用适当方式达到最终一致性。
# 2、BASE 的三要素详解
# 2.1、基本可用(Basically Available)
系统在出现故障时,允许损失部分可用性:
- 响应时间损失:正常 0.5 秒返回,高峰期可以 2 秒返回
- 功能损失:电商大促时,关闭商品评论、历史订单查询等非核心功能
- 服务降级:返回缓存数据或默认值
# 2.2、软状态(Soft State)
允许系统数据存在中间状态:
- 数据同步延迟:主从复制的延迟窗口
- 缓存不一致:缓存更新的时间窗口
- 状态转换:订单的"待支付→支付中→已支付"状态流转
# 2.3、最终一致性(Eventually Consistent)
系统保证在没有新更新的情况下,数据最终达到一致:
- 时间窗口:Amazon DynamoDB 保证 1 秒内达到一致
- 冲突解决:版本向量、时间戳、CRDT 等机制
- 补偿机制:对账、重试、人工介入
# 3、实践案例:Eureka vs ZooKeeper
| 特性 | Eureka (AP) | ZooKeeper (CP) |
|---|---|---|
| 设计理念 | 服务注册中心 | 分布式协调服务 |
| 一致性 | 最终一致性 | 强一致性 |
| 可用性 | 高可用,节点对等 | 主节点故障时短暂不可用 |
| 分区容错 | 优雅处理网络分区 | 少数派节点不可用 |
| 自我保护 | 有,防止误删服务 | 无 |
| 适用场景 | 微服务注册发现 | 配置管理、分布式锁 |
# 六、超越 CAP:现代分布式系统设计
# 1、CAP 的局限性
CAP 理论虽然重要,但它是一个相对粗粒度的理论框架:
- 二元选择过于简化:实际系统中,C、A、P 都不是二元的
- 忽略了延迟:网络延迟对系统设计同样重要
- 静态视角:没有考虑系统的动态调整能力
# 2、PACELC 理论
2012 年,Yale 大学的 Daniel Abadi 提出了 PACELC 理论,扩展了 CAP:
如果有分区(P),系统需要在可用性(A)和一致性(C)之间权衡;否则(Else),当系统正常运行时,需要在延迟(L)和一致性(C)之间权衡。
| 系统 | 分区时 | 正常时 | 说明 |
|---|---|---|---|
| Cassandra | PA | EL | 优先可用性和低延迟 |
| MongoDB | PA | EC | 分区时可用,正常时一致 |
| HBase | PC | EC | 始终优先一致性 |
| DynamoDB | PA | EL | 完全优先性能 |
# 3、动态权衡策略
现代系统通过动态调整来优化 CAP 权衡:
# 3.1、DataGuard 的三种模式
这是动态权衡的经典案例:
最大保护模式(Maximum Protection)
- 强同步复制,零数据丢失
- 主库写操作必须同步到至少一个备库
- 适用于关键金融数据
最大性能模式(Maximum Performance)
- 异步复制,最佳性能
- 可能丢失少量数据
- 适用于性能敏感的应用
最大可用性模式(Maximum Availability)
- 正常时同步,故障时异步
- 动态切换,平衡一致性和可用性
- 适用于大多数企业应用
# 3.2、可调一致性(Tunable Consistency)
Cassandra 等系统提供了可调一致性级别:
写一致性级别:
- ANY: 写入任意节点(包括 Hinted Handoff)
- ONE: 至少一个节点确认
- QUORUM: 多数节点确认
- ALL: 所有节点确认
读一致性级别:
- ONE: 从一个节点读取
- QUORUM: 从多数节点读取并返回最新值
- ALL: 从所有节点读取
一致性公式:W + R > N 保证强一致性(W=写副本数,R=读副本数,N=总副本数)
# 4、混合方案
现代系统常采用混合架构,不同组件选择不同的 CAP 权衡:
| 组件 | CAP选择 | 用途 |
|---|---|---|
| 配置中心 | CP | 存储关键配置,需要强一致 |
| 服务注册 | AP | 服务发现,可容忍短暂不一致 |
| 缓存层 | AP | 提升性能,数据可以过期 |
| 核心数据库 | CP | 存储关键业务数据 |
| 日志系统 | AP | 可以丢失少量日志 |
# 七、实战指南:如何在项目中应用 CAP
# 1、系统设计决策树
1. 数据是否允许丢失?
├─ 否 → 选择 CP
│ └─ 金融、库存、配置管理
└─ 是 → 继续判断
2. 是否需要实时响应?
├─ 是 → 选择 AP
│ └─ 社交、推荐、日志
└─ 否 → 根据业务权衡
3. 是否跨地域部署?
├─ 是 → 优先考虑 AP
└─ 否 → 可以考虑 CP
# 2、常见场景的 CAP 选择
| 业务场景 | CAP选择 | 具体方案 | 关键考虑 |
|---|---|---|---|
| 支付系统 | CP | 两阶段提交、TCC | 资金安全第一 |
| 库存扣减 | CP | 分布式锁、预扣库存 | 防止超卖 |
| 购物车 | AP | 最终一致性 | 用户体验优先 |
| 商品搜索 | AP | Elasticsearch | 可接受延迟更新 |
| 用户session | AP | Redis Cluster | 快速响应 |
| 配置中心 | CP | ZooKeeper/Etcd | 配置准确性 |
| 消息队列 | AP/CP可选 | Kafka(AP)/RabbitMQ(可配置) | 根据场景选择 |
# 3、技术选型建议
CP 系统技术栈:
- 协调服务:ZooKeeper、Etcd、Consul
- 数据库:TiDB、CockroachDB、Spanner
- 共识算法:Raft、Paxos、ZAB
AP 系统技术栈:
- NoSQL:Cassandra、DynamoDB、Riak
- 缓存:Redis Cluster、Memcached
- 服务发现:Eureka、Consul(AP模式)
可调节系统:
- MongoDB:可配置写关注级别
- Cassandra:可调一致性级别
- Consul:支持 CP 和 AP 模式切换
# 八、总结与展望
# 1、核心要点回顾
- CAP 不是绝对的三选二:在分布式系统中,P 是必须的,真正的权衡在 C 和 A 之间
- 一致性和可用性都有程度:不是非黑即白,而是连续的光谱
- 动态权衡是趋势:根据系统状态和业务需求动态调整
- 混合架构是常态:不同组件根据特性选择不同的 CAP 策略
# 2、未来发展方向
- NewSQL 数据库:尝试在 CP 基础上提供更好的可用性(如 Google Spanner)
- CRDT 技术:无冲突复制数据类型,自动解决并发冲突
- 区块链共识:将 CAP 理论应用于去中心化系统
- 边缘计算:在边缘场景下的 CAP 权衡新挑战
# 3、学习建议
- 理论结合实践:不只是理解概念,要在实际项目中应用
- 研究开源系统:深入学习 ZooKeeper、Cassandra、Etcd 等系统的设计
- 关注故障案例:学习大厂的故障复盘,理解 CAP 权衡的实际影响
- 持续跟进新技术:分布式系统领域发展迅速,保持学习
CAP 理论就像是分布式系统的"第一性原理",理解了它,你就掌握了分布式系统设计的基本规律。但记住,CAP 只是起点,不是终点。在实际工作中,你需要根据具体业务场景,灵活运用这些理论,做出最适合的架构决策。
愿你在分布式系统的道路上越走越远!